
Machine Learning Basic Tool: Pandas
What is Pandas?
Pandas is an open‑source Python library that makes it easy to work with tabular data – the kind you see in spreadsheets, SQL tables, or CSV files.
| Feature | Why it matters for ML |
|---|---|
| Labelled axes (rows & columns) | You can refer to data by names instead of only numeric positions – essential for readability. |
| Fast, vectorised operations. | Operations run in compiled C code under the hood, so they are much quicker than Python loops. |
| Rich I/O support | Load data from CSV, Excel, JSON, SQL, Parquet, and many more – hassle‑free. |
| Powerful data‑cleaning tools | Missing‑value handling, type conversion, duplicate removal – all done in a few lines. |
| Integration with ML ecosystem | Works hand‑in‑hand with NumPy, Scikit‑Learn, TensorFlow, PyTorch, and visualization libraries like Matplotlib & Seaborn. |
Bottom line: If you’ve ever spent hours wrestling with “dirty” data, Pandas is the shortcut that lets you focus on the model instead of the mess.
Data Structures & Types in Pandas
Pandas builds on NumPy (the fundamental array library). The two pillars you’ll use almost every day are:
| Structure | Description | Typical Use‑Case |
|---|---|---|
| Series | 1‑D labeled array (think of a single column). Supports any NumPy data type (int, float, object, datetime, etc.). | Holding a list of ages, a target vectory, or any one‑dimensional feature. |
| DataFrame | 2‑D table of Series objects sharing a common index (rows). Columns can have different data types. | The entire dataset – features (X) and optionally the target column. |
2.1 Series – a quick look
import pandas as pd
# Create a Series from a Python list
ages = pd.Series([23, 45, 31, 27], name='age')
print(ages)
0 23
1 45
2 31
3 27
Name: age, dtype: int64
The left‑hand numbers (0,1,2,3) are the index. You can assign your own:
ages = pd.Series([23, 45, 31, 27],
index=['Anna', 'Bob', 'Cathy', 'Dan'],
name='age')
print(ages)
Anna 23
Bob 45
Cathy 31
Dan 27
Name: age, dtype: int64
2.2 DataFrame – the workhorse
data = {
'name' : ['Anna', 'Bob', 'Cathy', 'Dan'],
'age' : [23, 45, 31, 27],
'salary' : [50000, 75000, 62000, 58000],
'dept' : ['HR', 'Engineering', 'Marketing', 'Finance']
}
df = pd.DataFrame(data)
print(df)
name age salary dept
0 Anna 23 50000 HR
1 Bob 45 75000 Engineering
2 Cathy 31 62000 Marketing
3 Dan 27 58000 Finance
Key points
- Rows are indexed automatically (
0…n-1), but you can set any column as the index withdf.set_index('name', inplace=True). - Columns have explicit names (
'age','salary', …) – you can access them like dictionaries (df['age']) or as attributes (df.age).
2.3 Data Types (dtypes)
Pandas tries to infer the best type, but you can check and enforce them:
print(df.dtypes)
name object
age int64
salary int64
dept object
dtype: object
Common dtype shortcuts
| dtype | Description |
|---|---|
int64 / float64 | Numeric, stored as 64‑bit integers/floats. |
object | Generic Python objects – usually strings. |
category | Optimized for text with few unique values (e.g., dept). |
datetime64[ns] | Timestamps, powerful for time‑series. |
You can cast a column to a more suitable type:
df['dept'] = df['dept'].astype('category')
df['hire_date'] = pd.to_datetime(['2020-02-15',
'2018-06-01',
'2019-11-20',
'2021-01-05'])
print(df.dtypes)
Importing & Exporting Data in Pandas
Real‑world ML pipelines usually start with reading raw data and end with saving the processed version (or model predictions). Pandas ships with a tidy collection of read_* and to_* functions.
| Format | Read Function | Write Function |
|---|---|---|
| CSV | pd.read_csv() | df.to_csv() |
| Excel | pd.read_excel() | df.to_excel() |
| JSON | pd.read_json() | df.to_json() |
| SQL (any DB) | pd.read_sql() | df.to_sql() |
| Parquet (columnar) | pd.read_parquet() | df.to_parquet() |
| HTML tables | pd.read_html() | (rarely needed) |
| Clipboard | pd.read_clipboard() | df.to_clipboard() |
3.1 Reading a CSV – the most common case
# Assume file "employee_data.csv" exists in the same folder
df = pd.read_csv('employee_data.csv',
sep=',', # delimiter – default is ','
header=0, # first row contains column names
na_values=['', 'NA'], # treat empty strings or "NA" as missing
dtype={'dept': 'category'}, # explicit dtype for a column
parse_dates=['hire_date']) # automatically parse dates
What if the CSV is huge?
| Method | When to use |
|---|---|
chunksize=10000 | Load the file in batches to keep memory low. |
usecols=['name','age'] | Load only a subset of columns you actually need. |
low_memory=False | Prevent internal type‑guessing that can cause warnings. |
for chunk in pd.read_csv('big_file.csv', chunksize=10_000):
# do something with each chunk, e.g., calculate running mean
print(chunk['sales'].mean())
3.2 Exporting a DataFrame
# Save to CSV – keep index? Usually set index=False unless it has meaning.
df.to_csv('clean_employee_data.csv', index=False)
# Save to Parquet (fast, compressed, columnar)
df.to_parquet('clean_employee_data.parquet', compression='snappy')
Tip: Parquet is the go‑to format for large datasets because it’s compressed and splittable, which makes distributed processing (Spark, Dask) much smoother.
Data Overview in Pandas
Before feeding data to a model, you need to understand its shape, distribution, and quirks. Pandas offers a small toolbox that instantly tells you the story of your table.
4.1 Quick glance – head, tail, shape
df.head() # first 5 rows (default)
df.tail(3) # last 3 rows
df.shape # (rows, columns) → (n, p)
4.2 Summary statistics – describe()
df.describe(include='all')
| Output | Meaning |
|---|---|
count | Non‑missing entries |
mean, std, min, max, 25%, 50%, 75% | Central tendency and spread for numeric columns |
unique, top, freq | For non‑numeric columns (e.g., most common department) |
Example
print(df['salary'].describe())
count 4.000000
mean 61250.000000
std 9672.120299
min 50000.000000
25% 54750.000000
50% 60000.000000
75% 66500.000000
max 75000.000000
Name: salary, dtype: float64
4.3 Data types & memory usage
print(df.info())
The output tells you:
- Number of rows, columns
- Data type of each column (including
categoryvsobject) - Memory footprint – essential when you’re close to RAM limits.
4.4 Missing values – isnull() & sum()
missing = df.isnull().sum()
print(missing)
name 0
age 0
salary 1
dept 0
hire_date 0
dtype: int64
You can also visualise missing patterns with a quick heat‑map (needs. seaborn):
import seaborn as sns
import matplotlib.pyplot as plt
sns.heatmap(df.isnull(), cbar=False, yticklabels=False, cmap='viridis')
plt.title('Missing‑value map')
plt.show()
4.5 Correlation matrix – corr()
corr = df[['age', 'salary']].corr()
print(corr)
age salary
age 1.000000 0.162221
salary 0.162221 1.000000
For a visual version:
sns.heatmap(corr, annot=True, cmap='coolwarm')
plt.title('Feature correlation')
plt.show()
Data Operations in Pandas
Once you’ve inspected the data, you’ll spend most of your time transforming it – cleaning, filtering, reshaping, and engineering new features. Below are the most frequently used operations, each with an example that you can copy‑paste into a notebook.
5.1 Selecting & Filtering
| Operation | Syntax | Example |
|---|---|---|
| Column selection | df['col'] or df.col | df['salary'] |
| Row slice (by position) | df.iloc[2:5] | rows 2‑4 inclusive |
| Row slice (by label) | df.loc[2:5] (if index are labels) | |
| Boolean filter | df[condition] | df[df['age'] > 30] |
| Multiple conditions | & (and) / ` | ` (or) + parentheses |
Example – keep only engineers older than 25
engineers = df[(df['dept'] == 'Engineering') & (df['age'] > 25)]
print(engineers)
5.2 Adding / Modifying Columns
# 1. Simple arithmetic
df['salary_k'] = df['salary'] / 1000 # new column in thousands
# 2. From existing columns – create a “tenure” feature
df['tenure_years'] = (pd.Timestamp('today') - df['hire_date']).dt.days / 365
# 3. Conditional assignment – flag high earners
df['high_earner'] = (df['salary'] > 70_000).astype(int) # 1 if true else 0
Result
name age salary dept hire_date salary_k tenure_years high_earner
0 Anna 23 50000 HR 2020-02-15 50.0 6.28 0
1 Bob 45 75000 Engineering 2018-06-01 75.0 8.00 1
2 Cathy 31 62000 Marketing 2019-11-20 62.0 6.86 0
3 Dan 27 58000 Finance 2021-01-05 58.0 5.43 0
5.3 Handling Missing Values
| Strategy | Code |
|---|---|
| Drop rows with any missing values | df.dropna(inplace=True) |
| Drop columns that are mostly missing | df.dropna(axis=1, thresh=int(0.7*len(df))) |
Fill with constant (e.g., 0 or 'unknown') | df['dept'].fillna('unknown', inplace=True) |
| Forward/backward fill – useful for time series | df['salary'].ffill(inplace=True) |
| Impute with mean/median (numeric) | df['age'].fillna(df['age'].median(), inplace=True) |
| Impute with mode (categorical) | df['dept'].fillna(df['dept'].mode()[0], inplace=True) |
Example – fill missing salaries with the median salary of the same department
# Compute median salary per department
dept_median = df.groupby('dept')['salary'].transform('median')
# Fill missing values using that median
df['salary'].fillna(dept_median, inplace=True)
5.4 Sorting & Rearranging
# Sort by age (ascending) then salary (descending)
df_sorted = df.sort_values(['age', 'salary'],
ascending=[True, False])
# Reset the integer index after sorting
df_sorted.reset_index(drop=True, inplace=True)
5.5 Aggregation & Group‑by
One of the most powerful Pandas patterns is group‑by → aggregation.
# Average salary per department
avg_salary = df.groupby('dept')['salary'].mean()
print(avg_salary)
dept
Engineering 75000.0
Finance 58000.0
HR 50000.0
Marketing 62000.0
Name: salary, dtype: float64
You can apply multiple aggregations at once:
dept_stats = df.groupby('dept').agg(
count=('salary', 'size'), # number of rows per group
avg_salary=('salary', 'mean'),
max_age=('age', 'max'),
min_hire=('hire_date', 'min')
)
print(dept_stats)
count avg_salary max_age min_hire
dept
Engineering 1 75000.00000 45 2018-06-01
Finance 1 58000.00000 27 2021-01-05
HR 1 50000.00000 23 2020-02-15
Marketing 1 62000.00000 31 2019-11-20
5.5.1 Using pivot_table for a spreadsheet‑like view
pivot = df.pivot_table(values='salary',
index='dept',
columns='high_earner',
aggfunc='mean',
fill_value=0)
print(pivot)
high_earner 0 1
dept
Engineering 0.00 75000.0
Finance 58000.0 0.00
HR 50000.0 0.00
Marketing 62000.0 0.00
5.6 Reshaping – melt, stack, unstack, pivot
Wide → Long with melt (useful for time‑series or feeding into certain models)
wide = pd.DataFrame({
'id': [1, 2],
'Jan': [100, 150],
'Feb': [110, 160],
'Mar': [115, 170]
})
long = wide.melt(id_vars='id', var_name='month', value_name='sales')
print(long)
id month sales
0 1 Jan 100
1 2 Jan 150
2 1 Feb 110
3 2 Feb 160
4 1 Mar 115
5 2 Mar 170
Long → Wide with pivot (opposite of melt)
restored = long.pivot(index='id', columns='month', values='sales')
print(restored)
month Feb Jan Mar
id
1 110 100 115
2 160 150 170
5.7 Applying Custom Functions – apply, map, lambda
# Example: categorize age groups
def age_group(age):
if age < 30:
return 'Young'
elif age < 45:
return 'Mid'
else:
return 'Senior'
df['age_group'] = df['age'].apply(age_group)
You can also use a simple lambda for one‑liners:
df['salary_bracket'] = df['salary'].map(lambda x: 'High' if x > 65_000 else 'Low')
5.8 Merging & Joining Datasets
When you have multiple tables (e.g., employee details + performance scores), you often need to join them.
# Create a second DataFrame with performance rating
perf = pd.DataFrame({
'name': ['Anna', 'Bob', 'Cathy', 'Dan'],
'rating': [4.2, 3.8, 4.5, 4.0]
})
# Inner join on the column "name"
merged = pd.merge(df, perf, on='name', how='inner')
print(merged)
Result:
name age salary dept hire_date salary_k tenure_years high_earner age_group salary_bracket rating
0 Anna 23 50000 HR 2020-02-15 50.0 6.28 0 Young Low 4.2
1 Bob 45 75000 Engineering 2018-06-01 75.0 8.00 1 Senior High 3.8
2 Cathy 31 62000 Marketing 2019-11-20 62.0 6.86 0 Mid Low 4.5
3 Dan 27 58000 Finance 2021-01-05 58.0 5.43 0 Young Low 4.0
Join types
how | Meaning |
|---|---|
'inner' | Keep only rows that appear in both tables. |
'left' | Keep all rows from the left table; missing values on the right are filled with NaN. |
'right' | Keep all rows from the right table. |
'outer' | Keep all rows from both tables (union). |
5.9 Vectorised Math – using NumPy together with Pandas
Because Pandas objects are built on top of NumPy arrays, you can freely apply NumPy functions:
import numpy as np
# Linear scaling of salary to a 0‑1 range
df['salary_scaled'] = (df['salary'] - df['salary'].min()) / (df['salary'].max() - df['salary'].min())
# Apply a custom NumPy ufunc (e.g., exponential)
df['exp_age'] = np.exp(df['age'])
Mathematical example – Standardizing a feature (z‑score)
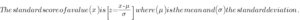
mu = df['salary'].mean()
sigma = df['salary'].std()
df['salary_z'] = (df['salary'] - mu) / sigma
print(df[['salary', 'salary_z']])
salary salary_z
0 50000 -0.727607
1 75000 1.227424
2 62000 0.298598
3 58000 -0.798415
Putting It All Together – Mini End‑to‑End Workflow
Below is a compact notebook‑style script that demonstrates a typical ML preprocessing pipeline using Pandas. Feel free to copy‑paste, run, and adapt to your own data.
# -------------------------------------------------------------
# 0 Imports
# -------------------------------------------------------------
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# -------------------------------------------------------------
# 1 Load raw data
# -------------------------------------------------------------
raw_path = 'employee_raw.csv'
df = pd.read_csv(raw_path,
na_values=['', 'NA'],
dtype={'dept': 'category'},
parse_dates=['hire_date'])
# -------------------------------------------------------------
# 2 Quick overview
# -------------------------------------------------------------
print('Shape:', df.shape)
print(df.head())
print(df.info())
print(df.describe(include='all'))
# -------------------------------------------------------------
# 3 Clean missing values
# -------------------------------------------------------------
# Example: fill missing salaries with department median
dept_median = df.groupby('dept')['salary'].transform('median')
df['salary'].fillna(dept_median, inplace=True)
# Fill other categorical NAs with mode
df['dept'].fillna(df['dept'].mode()[0], inplace=True)
# -------------------------------------------------------------
# 4 Feature engineering
# -------------------------------------------------------------
df['salary_k'] = df['salary'] / 1000
df['tenure_yr'] = (pd.Timestamp('today') - df['hire_date']).dt.days / 365
df['high_earner'] = (df['salary'] > 65_000).astype(int)
# Age grouping (simple example)
df['age_group'] = pd.cut(df['age'],
bins=[0, 30, 45, np.inf],
labels=['Young', 'Mid', 'Senior'])
# -------------------------------------------------------------
# 5 Encode categoricals for ML
# -------------------------------------------------------------
# Use pandas.get_dummies (one‑hot) – avoid dummy‑trap by dropping first
df_ml = pd.get_dummies(df,
columns=['dept', 'age_group'],
drop_first=True)
# -------------------------------------------------------------
# 6 Final inspection before modelling
# -------------------------------------------------------------
print('Prepared data shape:', df_ml.shape)
print(df_ml.head())
# Optional: visual sanity check of correlations
corr = df_ml.corr()
sns.heatmap(corr, cmap='RdBu_r', center=0,
linewidths=.5, cbar_kws={"shrink": .5})
plt.title('Correlation matrix of engineered features')
plt.show()
# -------------------------------------------------------------
# 7 Save cleaned data for the next step (model training)
# -------------------------------------------------------------
df_ml.to_parquet('employee_clean.parquet', compression='snappy')
What just happened?
| Step | Why it matters for ML |
|---|---|
| Load | Reads raw CSV while handling missing value markers and proper data types. |
| Overview | Guarantees you know the shape, types, and any glaring issues before you start. |
| Cleaning | Guarantees no NaNs that would crash Scikit‑Learn estimators. |
| Feature engineering | Turns raw columns into model‑ready numeric features (salary_k, tenure_yr, high_earner). |
| Encoding | Converts categorical strings to numeric 0/1 flags, a requirement for most algorithms. |
| Inspection | A quick correlation heat‑map reveals collinearity that might need removal. |
| Save | Persists the prepared dataset in an efficient columnar format for downstream pipelines. |
Frequently Asked Questions (FAQ)
| Question | Short Answer |
|---|---|
| Do I need Pandas for every ML project? | Not always. For tiny arrays, plain NumPy works. But as soon as you have heterogeneous columns, missing values, or need to join tables, Pandas saves hours. |
| Can Pandas handle >10 GB of data on a laptop? | Not comfortably. Use chunking (chunksize) or switch to a larger‑scale library like Dask or Polars, which mimics Pandas API but works out‑of‑core. |
What’s the difference between Series a single-column and a DataFrame? | A Series is 1‑D (has an index only). A single‑column DataFrame is 2‑D (has both index and column label). Some APIs require a DataFrame (e.g., sklearn expect 2‑D inputs). |
| Is Pandas fast enough for real‑time inference? | For serving predictions, you usually avoid Pandas and work directly with NumPy or PyTorch/TensorFlow tensors. Pandas shines during offline preprocessing. |
| How do I avoid “SettingWithCopyWarning”? | Use .loc for assignment (df.loc[row, col] = value) or assign the result of an operation to a new variable (df = df.dropna()). |
Takeaway Checklist
- Import Pandas (
import pandas as pd). - Read your data with the appropriate
read_*function. - Inspect using
head,info,describe, and missing‑value checks. - Clean: drop/fill missing values, convert dtypes, remove duplicates.
- Engineer features – scaling, encoding, date arithmetic, and custom columns.
- Aggregate/Group with
groupbyorpivot_tablefor summary stats. - Reshape using
melt,pivot,stack,unstackWhen the table orientation needs to be changed. - Merge/Join multiple tables with
merge. - Export the final tidy dataset (CSV for simplicity, Parquet for performance).
When you follow this roadmap, you’ll spend minutes on data wrangling instead of hours.
Final Thoughts
Pandas is more than just a “spreadsheet in Python.” It’s a full‑featured data manipulation engine that lets you:
- Read from any source with a single line of code.
- Explore your data instantly, spotting problems before they become bugs.
- Transform raw observations into clean, model‑ready matrices.
- Scale pipelines from a few rows to millions (with the right tricks).
The next time you start a machine‑learning project, let Pandas be the first tool you reach for. Master the operations above, and you’ll be equipped to handle any tabular dataset that comes your way.
Explore More IT Terms
#
A
- A Guide to SQL Query Formatting
- A/B testing
- Agile
- Algorithm
- Algorithm complexity in 5 minutes
- Algorithms and Data Structures in C#
- An overview of the C # programming language
- An overview of the Python programming language
- Anaconda Python
- Android
- Android App Bundle
- Android SDK
- Angular
- Ansible
- Apache
- Apache Airflow
- Apache Kafka
- Apache Tomcat
- App Store
- AppCode
- Applications of microcontrollers: From simple circuits in electronics to complex systems
- Applications of the derivative
- Arduino: How to Program It: Basics for Beginners
- Array-based stack
- ArrayList
- ASCII
- ASP.NET
- Assembly Language Lessons
B
C
D
- Data Analytics: applications of data analysis in companies
- Data Engineer - Who is it, what does a data engineer do, and an overview of the profession
- Data modeling: what it is, types, and process steps.
- Data preprocessing: a complete guide for beginners and professionals.
- Data structure
- Deep Learning
- Defining Aliases
- Defining Arrays
- Deque
- Developing a Website from Scratch
- Differential Equations
- Differentiation of functions
- Digital data: understand the importance of this asset for businesses.
- Double integrals
- Doubly linked lists
E
F
H
- Handling errors and exceptions
- History of the development of computer science
- How to effectively organize your workflow
- How to Learn Java: Tips for Beginner Developers
- How to Learn PHP: A Beginner's Guide
- How to Use S3 Storage in Kubernetes with CSI
- HTML
- HTML and CSS: Definition, Application, and Operating Principles
- HTML and CSS. Layout from Scratch: What to Learn, Where to Learn, and How Long Will It Take?
- HTML Frame Structure
- HTML Link Formatting
I
- if..else construction
- Infinite sequences and series
- Information properties
- Inheritance in Java: A Complete Guide to Principles and Implementation
- Inserting an Image
- Integration of functions
- Interactive Python Tutorial – Learn Programming from Scratch
- Interview Problem: Finding a Deleted Element in O(N)
- Interview Scare: The FizzBuzz Challenge
- Introduction to C++
- Introduction to Machine Learning
- Introduction to programming languages
- IT Specialist Resume (CV)
J
K
M
- Machine Learning
- Machine Learning Basic Tool: NumPy
- Machine Learning Basic Tool: Pandas
- Machine Learning Mathematics
- Microcontroller and Microprocessor - what's the difference?
- ML Engineer: Who They Are, What They Do, How Much They Earn, and How to Become a Neural Network Specialist
- Monte Carlo Simulation: How It Works and What It's For
O
P
- PHP lessons
- Private DNS server and its configuration
- Programmer's Dictionary
- Programming with pseudocode
- Python Code Formatting Guide: PEP8
- Python for data analysis: how to do it and main libraries
- Python Lessons
- Python Superstar: 5 Ways to Use the * Operator
- Python vs. Julia: Should You Replace Python with Julia?
R
S
- SFML Graphics Library Tutorials
- Sorting Algorithms in Programming: Types, Descriptions, and Comparisons
- SQL commands: see what they are, what the main ones are + examples
- SQL Interview Questions and Tasks
- SQL Lessons
- SQL Stored Procedures
- SQL Syntactic Sugar: The COALESCE Function
- Stack
- Start in analytics: Python or R
- Statistical analysis: importance for decision making.
- String formatting in Python
- Structure of computer science
- Swift Lessons
- switch/match construct
T
- Terms in programming
- Text and paragraph formatting tags
- The concept of information and its transmission
- The Future of Python: Key Trends and Insights from Global Researc
- The pip package manager in Python
- The role of informatization in the development of society
- Transfers
- Tutorials / Articles
- TypeScript: What It Is and Why Developers Need It
W
- What are databases, and why do they need DBMS and SQL?
- What do Linux distributions consist of?
- What is .NET and what is it used for?
- What is a GPU in a computer, in simple terms?
- What is Arduino: How it Works and the Platform's Capabilities
- What is Big Data? Introduction, Types, Characteristics, and Examples
- What is Golang and what is it used for?
- What is Haskell and what is it used for?
- What is Kotlin and what is it used for?
- What is Linux? The History of Linux
- What is machine learning, and how does it work?
- What is Power BI: everything about the data analytics software
- What is the C++ programming language?
- What is the OSI Model: A Complete Explanation of the Seven Layers and Their Role in Networking
- What's the difference between x86 and ARM processors?
- Where to start learning the C programming language?
- Which Linux distribution should you choose? A Linux distribution overview