Fundamentals of Algorithms and Data Structures
Introduction to Algorithms
An algorithm is a sequence of steps designed to solve a specific problem. In other words, an algorithm is a method for solving this problem. In this sense, the term “algorithm” is used to describe a method for solving any problem, including everyday ones. However, in this case, we will be discussing algorithms for computer calculations.
The term “algorithm” itself comes from the name of the Persian mathematician Al-Khwarizmi, whose works played an important role in the development of mathematics as a science.
An algorithm may have input data on which calculations are performed, and it may also have an output—a single value or a set of values. Essentially, the algorithm’s task is to transform input values into output values.
An important criterion for an algorithm is its efficiency. An algorithm can perfectly solve a given problem, but still be inefficient. Typically, algorithm efficiency refers to the time it takes to execute.
The total execution time of the program depends on two factors:
- execution time of each operator
- frequency of execution of each operator
The execution time of each statement depends on the execution environment, operating system, and other system characteristics.
Depending on their efficiency, there are many types of algorithms, among which the following types of algorithms can be distinguished (listed in order of decreasing efficiency):
- Constant (1)An application performs a fixed number of operations that typically require constant time.
An example would be the following set of operations:
123456789int x = 10;
if(x > 0)
{
x--;
}
else
{
x++;
} - Logarithmic (logN)It runs slower than constant-time programs. An example of such an algorithm is the binary search algorithm.12345678910111213141516
public static int Rank(int key, int[] numbers)
{
int low = 0;
int high = numbers.Length - 1;
while (low <= high)
{
// find the middle
int mid = low + (high - low) / 2;
// if the search key is less than the value in the middle
// then the upper bound will be the element before the middle
if (key < numbers[mid]) high = mid - 1;
else if (key > numbers[mid]) low = mid + 1;
else return mid;
}
return -1;
}For example, if we have
numbers8 elements in an array, then to find the element we need, we need to sequentially divide the number of elements by 2. That is, to find the desired element, we need to execute the while loop 3 times. And this result is precisely described by the logarithmic function: log 2 8 = 3;The growth of execution time with the growth of N will increase by some constant value.
- Linear (N)Typically found where the method is based on a loop. For example, the factorial function:123456789
private static int Factorial(int n)
{
int result = 1;
for(int i=1; i<=n; i++)
{
result *= i;
}
return result;
}Here, the method’s execution depends on n. The number of times the loop will be executed depends on the value of n passed to the method. This means that the increase in the algorithm’s complexity for this method is proportional to the value of n, which is why it is called linear.
- Linear-logarithmic (NlogN)An example of such an algorithm is merge sort.
- Quadratic (N 2 )Typically, methods that correspond to this algorithm contain two loops – an outer loop and a nested loop – that are executed for all values up to N. An example would be a bubble sort program for an N-element array, in which, in the worst case, we need to iterate through N*N elements using two loops:12345678910111213141516
private static void BubbleSort(int[] nums)
{
int temp;
for (int i = 0; i < nums.Length - 1; i++)
{
for (int j = i + 1; j < nums.Length; j++)
{
if (nums[i] > nums[j])
{
temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
}
} - Cubic (N 3 )Programs that follow this algorithm use three loops, for example:1234567891011
char[] chars = new char[] { 'A', 'B', 'C' };
for(int i=0; i<chars.Length; i++)
{
for(int j=0; j<chars.Length;j++)
{
for(int k=0; k<chars.Length;k++)
{
Console.WriteLine($"{chars[i]}{chars[j]}{chars[k]}");
}
}
}
Here we’ve only discussed a few of the many types of algorithmic complexity that exist. They can be represented graphically as follows:
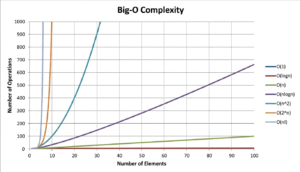
At the same time, several caveats should be made. This example presents an idealized model of algorithm complexity. But first, it’s important to note that this assumes the impact of the environment (the operating system) on program execution is negligible. However, in reality, the environment can naturally contribute to the final performance of an application.
Furthermore, in most cases, the complexity of an algorithm depends on the presence of loops. A method without a loop with simple expressions has O(1) complexity, while a method with a single loop has O(N) complexity, which is theoretically worse than O(1). However, in reality, the presence of simple operators, even without a loop, can reduce performance. Much here again depends on the specific logic of the program.
Another aspect that can impact program execution is caching. Using caching allows for faster re-execution of an operation. Therefore, the execution time of the same operation may vary.
Explore More IT Terms
#
A
- A Guide to SQL Query Formatting
- A/B testing
- Agile
- Algorithm
- Algorithm complexity in 5 minutes
- Algorithms and Data Structures in C#
- An overview of the C # programming language
- An overview of the Python programming language
- Anaconda Python
- Android
- Android App Bundle
- Android SDK
- Angular
- Ansible
- Apache
- Apache Airflow
- Apache Kafka
- Apache Tomcat
- App Store
- AppCode
- Applications of microcontrollers: From simple circuits in electronics to complex systems
- Applications of the derivative
- Arduino: How to Program It: Basics for Beginners
- Array-based stack
- ArrayList
- ASCII
- ASP.NET
- Assembly Language Lessons
B
C
D
- Data Analytics: applications of data analysis in companies
- Data Engineer - Who is it, what does a data engineer do, and an overview of the profession
- Data modeling: what it is, types, and process steps.
- Data preprocessing: a complete guide for beginners and professionals.
- Data structure
- Data structures
- Deep Learning
- Defining Aliases
- Defining Arrays
- Deque
- Developing a Website from Scratch
- Differential Equations
- Differentiation of functions
- Digital data: understand the importance of this asset for businesses.
- Double integrals
- Doubly linked lists
E
F
H
- Handling errors and exceptions
- How to effectively organize your workflow
- How to Learn Java: Tips for Beginner Developers
- How to Learn PHP: A Beginner's Guide
- How to Use S3 Storage in Kubernetes with CSI
- HTML
- HTML and CSS: Definition, Application, and Operating Principles
- HTML and CSS. Layout from Scratch: What to Learn, Where to Learn, and How Long Will It Take?
- HTML Frame Structure
- HTML Link Formatting
I
- if..else construction
- Infinite sequences and series
- Inheritance in Java: A Complete Guide to Principles and Implementation
- Inserting an Image
- Integration of functions
- Interactive Python Tutorial – Learn Programming from Scratch
- Interview Problem: Finding a Deleted Element in O(N)
- Interview Scare: The FizzBuzz Challenge
- Introduction to C++
- Introduction to Machine Learning
- Introduction to programming languages
- IT Specialist Resume (CV)
J
K
M
- Machine Learning
- Machine Learning Basic Tool: NumPy
- Machine Learning Basic Tool: Pandas
- Machine Learning Mathematics
- Microcontroller and Microprocessor - what's the difference?
- ML Engineer: Who They Are, What They Do, How Much They Earn, and How to Become a Neural Network Specialist
- Monte Carlo Simulation: How It Works and What It's For
O
P
- PHP lessons
- Private DNS server and its configuration
- Programmer's Dictionary
- Programming with pseudocode
- Python Code Formatting Guide: PEP8
- Python for data analysis: how to do it and main libraries
- Python Lessons
- Python Superstar: 5 Ways to Use the * Operator
- Python vs. Julia: Should You Replace Python with Julia?
R
S
- SFML Graphics Library Tutorials
- Sorting Algorithms in Programming: Types, Descriptions, and Comparisons
- SQL commands: see what they are, what the main ones are + examples
- SQL Interview Questions and Tasks
- SQL Lessons
- SQL Stored Procedures
- SQL Syntactic Sugar: The COALESCE Function
- Stack
- Start in analytics: Python or R
- Statistical analysis: importance for decision making.
- String formatting in Python
- Swift Lessons
- switch/match construct
T
W
- What are databases, and why do they need DBMS and SQL?
- What do Linux distributions consist of?
- What is .NET and what is it used for?
- What is a GPU in a computer, in simple terms?
- What is Arduino: How it Works and the Platform's Capabilities
- What is Big Data? Introduction, Types, Characteristics, and Examples
- What is Golang and what is it used for?
- What is Haskell and what is it used for?
- What is Kotlin and what is it used for?
- What is Linux? The History of Linux
- What is machine learning, and how does it work?
- What is Power BI: everything about the data analytics software
- What is the C++ programming language?
- What is the OSI Model: A Complete Explanation of the Seven Layers and Their Role in Networking
- What's the difference between x86 and ARM processors?
- Where to start learning the C programming language?
- Which Linux distribution should you choose? A Linux distribution overview