
Apache Kafka
Apache Kafka is a distributed messaging system for real-time exchange between server applications. Thanks to its high throughput, scalability, and reliability, it is used by companies working with large volumes of data. It is written in Java and Scala.
Kafka was developed by LinkedIn. In 2011, the developer published the system’s source code. Since then, the platform has been developed and maintained as an open source project by the Apache Software Foundation. Apache Kafka is used by many large companies, such as LinkedIn, Microsoft, The New York Times, Netflix, and others.

Using Apache Kafka
Apache Kafka is an effective tool for organizing server projects of any scale. Thanks to its flexibility, scalability, and fault tolerance, it is used in various IT applications, from streaming video services to big data analytics.
- For connecting microservices. Kafka is the link between individual functional modules of a larger system. For example, it can be used to subscribe to a microservice to receive regular updates.
- Streaming data. The system’s high throughput allows for continuous data flows. Thanks to intelligent routing, Kafka not only reliably transfers data but also enables various operations with it.
- Event logging. Kafka stores data in a strictly organized structure, allowing you to always track when a particular event occurred. Information is stored for a specified period of time, which can be used to reduce database load or slow logging systems.
How Apache Kafka Works
Briefly, the architecture of the message system can be characterized as follows:
- Distributed design— individual system nodes are located on multiple hardware platforms (clusters). This ensures high fault tolerance.
- Scalability – the system can be expanded by simply adding new nodes (message brokers).
The key concepts in Apache Kafka’s architecture are:
- producer – an application or process that generates and sends data (publishes a message);
- consumer – an application or process that receives a message generated by a producer;
- message – a data packet required to perform some operation (for example, authorization, purchase, or subscription);
- broker – a node (dispatcher) that transmits messages from the producer process to the consumer application;
- topic (subject) – a virtual storage of messages (log of records) of the same or similar content, from which the consuming application extracts the information it needs.
In a simplified form, Apache Kafka works as follows:
- The producer application creates a message and sends it to the Kafka node.
- The broker stores the message in a topic to which consumer applications are subscribed.
- If necessary, the consumer makes a request to the topic and receives the required data from it.
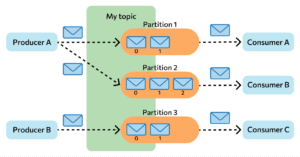
Messages are stored in Kafka as a commit log—records placed in a strict sequence. They can only be added; they cannot be deleted or edited. Messages are stored in the order in which they were received, read from left to right, and tracked by changes to their sequence numbers. Kafka brokers do not process the records—they only place them in a topic on the cluster. Retention can last for a specified period or until a specified threshold is reached.
If a topic grows too large, it’s divided into sections to simplify and speed up the process. Each section contains messages grouped by a unifying characteristic. For example, an array of user queries can be grouped by the first letter of the user’s name. This way, the consuming application doesn’t have to scan the entire topic—only the relevant one—which speeds up the message exchange process.
Benefits of Kafka
Fault tolerance
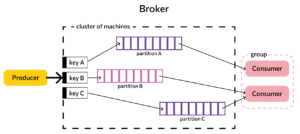
Kafka is a distributed messaging system whose nodes are located on multiple clusters. When receiving a message from a producer, it replicates it (copies) and stores the copies on different nodes. One broker is designated as the leader in a partition; consumers access records through it. The other brokers remain followers; their main task is to ensure the integrity of the message (or its copies) even if one or more nodes fail. The distributed nature and replication mechanism of the record ensure high resilience of the system.
Scalability
Apache Kafka supports hot expansion, meaning it can be expanded by simply adding new machines to clusters without shutting down the entire system. This eliminates downtime associated with reconfiguring server capacity. This approach is more convenient than horizontal scaling, which involves adding additional resources (hard drives, CPU, RAM, etc.) to a single server machine. If necessary, the system can be easily scaled down by removing unnecessary machines from the cluster.
Performance
In Kafka, message generation/sending and reading processes are organized independently. Thousands of applications and processes can simultaneously and in parallel act as message generators and consumers. Combined with its distributed nature and scalability, this allows Kafka to be used in both small and large-scale projects with large volumes of data.
Open source code
Kafka is distributed under a free license from the Apache Software Foundation. This gives Apache Kafka several advantages:
- A large volume of detailed reference information from official developers, as well as various manuals, life hacks, instructions, and reviews from a large number of amateur and professional enthusiasts.
- a large number of additional software packages and patches from third-party developers that expand and improve the basic functionality of the system;
- The ability to independently adapt the system to the specifics of the project due to the flexibility of the settings.
Safety
Kafka includes tools that ensure safe operation and data reliability. For example, by configuring the transaction isolation level, you can prevent unfinished or canceled messages from being read. Furthermore, by storing data in topics, users can track changes in the system at any time. And the sequential write principle allows for quick retrieval of relevant messages.
Durability
Kafka stores data in long-term virtual storage for a specified period of time (days, weeks, or months). Distributed storage ensures that information is not lost if one or more nodes fail, and consumers can access a specific message in a topic at any time, tracking its progress.
Integrability
Thanks to its native TCP-based protocol, Kafka interoperates with other data transfer protocols ( REST, HTTP, XMPP, STOMP, AMQP, MQTT). The built-in Kafka Connect framework allows Kafka to connect to databases, file storage, and cloud storage.
The system’s only noticeable drawback is its focus on processing large volumes of data. Because of this, its stream routing functionality is limited compared to other similar platforms. As Kafka matures, this difference will become less noticeable, and the system itself will become more flexible and versatile.
Explore More IT Terms
#
A
- A Guide to SQL Query Formatting
- A/B testing
- Agile
- Algorithm complexity in 5 minutes
- Algorithms and Data Structures in C#
- An overview of the C # programming language
- An overview of the Python programming language
- Anaconda Python
- Android
- Android App Bundle
- Android SDK
- Angular
- Ansible
- Apache
- Apache Airflow
- Apache Kafka
- Apache Tomcat
- App Store
- AppCode
- Applications of the derivative
- Array-based stack
- ArrayList
- ASCII
- ASP.NET
- Assembly Language Lessons
B
C
D
- Data Analytics: applications of data analysis in companies
- Data Engineer - Who is it, what does a data engineer do, and an overview of the profession
- Data modeling: what it is, types, and process steps.
- Data preprocessing: a complete guide for beginners and professionals.
- Data structure
- Data structures
- Defining Aliases
- Defining Arrays
- Deque
- Developing a Website from Scratch
- Differential Equations
- Differentiation of functions
- Digital data: understand the importance of this asset for businesses.
- Double integrals
- Doubly linked lists
E
F
H
- Handling errors and exceptions
- How to effectively organize your workflow
- How to Learn Java: Tips for Beginner Developers
- How to Learn PHP: A Beginner's Guide
- How to Use S3 Storage in Kubernetes with CSI
- HTML
- HTML and CSS: Definition, Application, and Operating Principles
- HTML and CSS. Layout from Scratch: What to Learn, Where to Learn, and How Long Will It Take?
- HTML Frame Structure
- HTML Link Formatting
I
- if..else construction
- Infinite sequences and series
- Inheritance in Java: A Complete Guide to Principles and Implementation
- Inserting an Image
- Integration of functions
- Interactive Python Tutorial – Learn Programming from Scratch
- Interview Problem: Finding a Deleted Element in O(N)
- Interview Scare: The FizzBuzz Challenge
- Introduction to C++
- Introduction to Machine Learning
- Introduction to programming languages
- IT Specialist Resume (CV)
J
K
M
O
P
- PHP lessons
- Private DNS server and its configuration
- Programmer's Dictionary
- Programming with pseudocode
- Python Code Formatting Guide: PEP8
- Python for data analysis: how to do it and main libraries
- Python Lessons
- Python Superstar: 5 Ways to Use the * Operator
- Python vs. Julia: Should You Replace Python with Julia?
S
- SFML Graphics Library Tutorials
- SQL commands: see what they are, what the main ones are + examples
- SQL Interview Questions and Tasks
- SQL Lessons
- SQL Stored Procedures
- SQL Syntactic Sugar: The COALESCE Function
- Stack
- Start in analytics: Python or R
- Statistical analysis: importance for decision making.
- String formatting in Python
- Swift Lessons
- switch/match construct
T
W
- What are databases, and why do they need DBMS and SQL?
- What do Linux distributions consist of?
- What is .NET and what is it used for?
- What is a GPU in a computer, in simple terms?
- What is Big Data? Introduction, Types, Characteristics, and Examples
- What is Golang and what is it used for?
- What is Haskell and what is it used for?
- What is Kotlin and what is it used for?
- What is Linux? The History of Linux
- What is machine learning, and how does it work?
- What is Power BI: everything about the data analytics software
- What is the C++ programming language?
- What is the OSI Model: A Complete Explanation of the Seven Layers and Their Role in Networking
- What's the difference between x86 and ARM processors?
- Where to start learning the C programming language?
- Which Linux distribution should you choose? A Linux distribution overview