
Before proceeding to the introduction to big data, you have to learn.
What is data?
Data is quantitative values, symbols, or characters that are processed using a computer and that can be stored and sent as electrical impulses on magnetic, optical, or mechanical media.
Let us examine what the definition of big data is.
What is big data?
Big data is a huge amount of information growing exponentially in time. The information is too big and complicated for any conventional software tools to analyze and store it properly. So big data is data on a massive scale.
What are the examples of big data?
Here are several examples of big data.
The New York Stock Exchange produces about one terabyte of new information every day.
Social networks
According to statistics, more than 500 terabytes of new information are added to the social media databases of Facebook daily. Most of the information is collected from photo and video uploading, messaging, comments, and other actions.
One jet engine produces 10 terabytes of information during 30 minutes of flight. And the total information becomes petabytes when there are a lot of flights daily.
Types of Big Data
Below are the types of big data:
- Structured
- Unstructured
- Semi-structured
Structured
Any data that can be stored, accessed, and processed in a fixed format is called “structured” data. Over time, computer science talent has made great strides in developing…ping There are methods for working with such data (whose format is known in advance) that allow us to extract value from it. However, today we foresee problems as the size of such data increases significantly, typically reaching several zettabytes.
Did you know? 10 21 bytes equals 1 zettabyte or one billion terabytes of the zettabyte form.
Looking at these figures, it is easy to understand why it is called “big data” and to imagine the problems associated with storing and processing it.
Did you know? Data stored in a relational database management system is one example of a ‘structured’ field.
Examples of structured data
The Employee table in a database is an example of structured data.
| Employee ID | Employee’s name | floor | Department | Salary_In_lacs |
|---|---|---|---|---|
| 2365 | Rajesh Kulkarni | M | Financial | 650,000 |
| 3398 | Pratibha Joshi | F | Admin | 650,000 |
| 7465 | Shushil Roy | M | Admin | 500,000 |
| 7500 | Shubhojit Das | M | Financial | 500,000 |
| 7699 | Priya Sane | F | Financial | 550,000 |
Unstructured
Any data with an unknown form or structure is classified as unstructured data. In addition to its enormous size, unstructured data poses numerous challenges in processing it for use. A typical example of unstructured data is a heterogeneous data source containing a combination of simple text files, images, videos, and so on. Today, organizations have vast amounts of accessible data, but unfortunately, they don’t know how to extract value from it because it is unprocessed or unstructured.
Examples of unstructured data
The result returned by the Google search.
Semi-structured
Semi-structured data can contain both forms of data. We can think of semi-structured data as structured in form, but in reality, it is not defined by, for example, a relational table definition. An example of semi-structured data is data represented in an XML file.
Examples of semi-structured data
Personal data stored in an XML file
<records> <rec> <name>Prashant Rao</name> <sex>Male</sex> <age>35</age> </rec> <rec> <name>Seema R.</name> <sex>Female</sex> <age>41</age> </rec> <rec> <name>Satish Mane</name> <sex>Male</sex> <age>29</age> </rec> <rec> <name>Subrato Roy</name> <sex>Male</sex> <age>26</age> </rec> <rec> <name>Jeremiah J.</name> <sex>Male</sex> <age>35</age> </rec> </records>
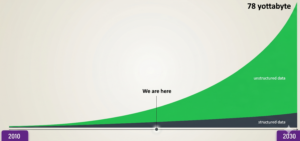
Data growth over the years
Please note that in a web application, unstructured data consists of log files, transaction history files, etc. OLTP systems are designed to work with structured data, where data is stored in relationships (tables).
Characteristics of Big Data
Big data can be described by the following characteristics:
- Volume
- diversity
- Speed
- Variability
(i) Volume – The very name “big data” derives from its sheer size. Data size plays a crucial role in determining its value. Furthermore, whether specific data can actually be considered big data depends on its volume. Therefore, “volume” is one of the characteristics that must be considered when working with big data solutions.
(ii) Diversity – The next aspect of big data is its diversity.
Diversity refers to the heterogeneous sources and nature of data, both structured and unstructured. Previously, spreadsheets and databases were the only data sources considered by most applications. Today, analytics applications also consider data in the form of emails, photos, videos, monitoring devices, PDFs, audio, and more. This diversity of unstructured data creates specific challenges for data storage, analysis, and insight.
(iii) Velocity – The term ‘velocity’ refers to the rate at which data is generated. How quickly data is generated and processed to meet demand determines the real potential of the data.
The velocity of big data refers to the speed at which data comes from sources such as business processes, application logs, networks, social media sites, sensors, mobile devices, etc. The flow of data is huge and continuous.
(iv) Variability – This refers to the inconsistency that may appear in the data from time to time, which makes it difficult to process and manage the data effectively.
Benefits of Big Data Processing
The ability to process big data in a DBMS provides many benefits, such as:
- Companies can use external information in decision-making
Access to social data from search engines and sites like Facebook and Twitter allows organizations to fine-tune their business strategies.
- Improved customer service
Traditional customer feedback systems are being replaced by new systems developed using big data technologies. These new systems use big data and natural language processing technologies to read and evaluate consumer responses.
- Early identification of risk to a product/service, if any.
- Better operational efficiency
Big data technologies can be used to create a staging area or landing zone for new data before determining which data should be moved to a data warehouse. Furthermore, this integration of big data and data warehouse technologies helps an organization offload rarely accessed data.
Summary
- Definition of Big Data: Big data refers to data of enormous size. “Big data” is a term used to describe a massive collection of data that grows exponentially over time.
- Examples of big data analysis include stock exchanges, social media sites, jet engines, etc.
- Big data can be 1) structured, 2) unstructured, or 3) semi-structured.
- Volume, variety, velocity, and volatility are just a few characteristics of big data.
- Improving customer service, increasing operational efficiency, and improving decision-making are just some of the benefits of big data.